Daton doesn’t prefer replicating your data in real-time, but why? Because it is not productive for most of our users if you consider technical and cost factors. Let us see what should be the right latency for all your data replication jobs.
Data Latency in Data Warehouse
Data latency is the time it takes for your data to become available in your database or data warehouse after an event occurs. Data latency can affect the quality and accuracy of your data analytics, as well as the performance of your data-driven applications. Therefore, it is important to measure and optimize data latency in your data warehouse.
One way to measure data latency in your data warehouse is to compare the timestamps of the events with the timestamps of the corresponding records in the data warehouse. This can give you an idea of how long it takes for your data pipeline to collect, transform, and load the data from various sources into your data warehouse. However, this method may not account for late-arriving data, which can cause discrepancies and inconsistencies in your data warehouse.
Another way to measure data latency in your data warehouse is to use a dedicated tool or service that monitors and reports on your data pipeline performance. For example, Snowplow provides a dashboard that shows the average and maximum latency of your data ingestion, as well as the distribution of latency across different stages of your data pipeline. This can help you identify and troubleshoot any bottlenecks or issues that may cause high data latency in your data warehouse.
Latency Data Collection
Latency data collection refers to the process of capturing and storing the latency metrics of your data pipeline. Latency data collection can help you analyze and optimize your data pipeline performance, as well as diagnose and resolve any problems that may affect your data quality and availability.
There are different methods and tools for latency data collection, depending on the type and source of your data. For example, if you are collecting log data from Azure resources, you can use Azure Monitor to track and report the ingestion time of your log data. Azure Monitor also provides alerts and notifications for any abnormal or unexpected changes in your log data ingestion time.
If you are collecting event data from web or mobile applications, you can use Adobe Analytics to measure and report on the latency of your data collection servers. Adobe Analytics also provides information on how latency affects your report suite processing and availability.
If you are collecting sensor data from battery-free wireless sensor networks (BF-WSNs), you can use latency-efficient data collection scheduling algorithms to minimize the latency of your data collection. These algorithms take into account the energy harvesting and communication constraints of BF-WSNs, as well as the network topology and traffic patterns.
Real-Time Data Replication
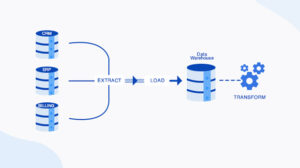
Daton replicates data to popular data warehouses like Google BigQuery, Amazon Redshift, Snowflake, and MySQL. Businesses use these data warehouses as the framework for effective data analytics. Data warehouses use columnar datastores to arrange data that analysts will access efficiently. This architectural design makes it easier to extract data for analysis, but at the same time, it becomes unsuitable for row-oriented updates in online transaction processing (OLTP).
The most productive way to load data into Amazon Redshift is with the COPY command. This command allocates the workload to the cluster nodes and also performs the load operations simultaneously. You get rows sorted and data distributed across node slices. Redshift documentation claims that one can add data to the tables using INSERT commands, but it is not as effective as the COPY command. Instead, inserting a single row takes a longer time than adding bulk records.
Real-time replication can downgrade the performance of a data warehouse. It delays the data loading process, using up processing resources that otherwise can be utilized in creating reports.
Right Latency for Data Analytics
Several Brands use Daton regularly, hence we have come to the conclusion that the 15 to 20 minutes of latency that the data sources provide is ideal for optimizing data warehouse performance and enhancing data analytics. Daton is optimized accordingly so that the users do not have to compromise with data warehouse performance and avoid unnecessary costs.
Powerful data analytics does not depend on fast data replication. It is always not true that real-time data will give you effective BI. The most important thing is how your organization is utilizing data analytics. The most important use is to provide the managers with relevant information for making better decisions. So, in this case, faster updates of your BI dashboards will not make you the winner.
For most businesses and use cases, a few minutes of old data is sufficiently updated. How fast are your teams and systems making decisions? In most situations, it will be several minutes, or hours, decision making might also take days.
There are business requirements where near-real-time loading of replicated data will benefit. Let us take an example of an automated chatbot for attending to customers’ inquiries. Here, it needs to know the context of the customer’s most recent interaction; hence the right latency will be a few seconds. Whereas, in the health sector, more than a second’s latency is detrimental when you have to analyze data from a heart monitoring implant. Similarly, algorithmic trading in the stock markets requires microsecond-updated pricing information.
You might need right real-time latency depending on what you need to do with your data. To make the data replication process cost-effective, you need to understand the use case of a specific data set. Data replication will be easily and effectively performed using cloud data pipelines.
Daton is an automated data pipeline that extracts from multiple sources for replicating data into data lakes or cloud data warehouses like Snowflake, Google Bigquery, and Amazon Redshift where employees can use it for business intelligence and data analytics. It has flexible loading options which will allow you to optimize data replication by maximizing storage utilization and easy querying. Daton provides robust scheduling options and guarantees data consistency. The best part is that Daton is easy to set up even for those without any coding experience. It is the cheapest data pipeline available in the market. Sign up for a free trial of Daton today.