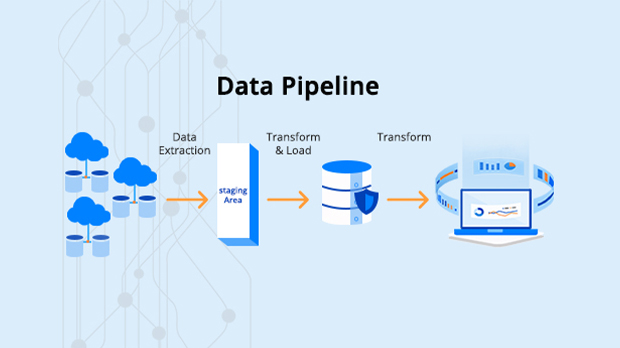
Organizations rely on their factual data to make all critical decisions – demand planning, forecast market and predict trends, production planning, and enhancing customer support and relationship management. Getting an organization’s data together for this purpose is the main objective of Data ingestion. This process moves data from various data sources into one place so that the data can be used further to draw insights and the architecture that supports this process is called Data Pipeline. Data Pipeline is an architecture of a system that captures, organizes, and routes the data to be utilized further in data analytics. ETL is a subprocess in a data pipeline architecture.
The history of the data pipeline goes back to the time when we used to manually update data in tables using data entry operators. It consisted of a lot of man-made mistakes and hence the need of data upload at frequent intervals without any human intervention became the necessity mainly in case of sensitive data such as banks insurance companies etc. During this time the transactional data used to get uploaded every night to ensure the next day the data is ready to use. This was a more convenient way, and slowly we moved to the intervals that could be defined for these data uploads. There still was a time lag as even for critical transactions users would have to wait until the next day for acting upon their data. Real-time data availability is a new need now. Today building the data pipeline to cloud services is essential to moving the organization’s data in real-time between on-premises and the cloud environment. In recent times the ETL pipeline which is running on AWS is a recommended one in practice.
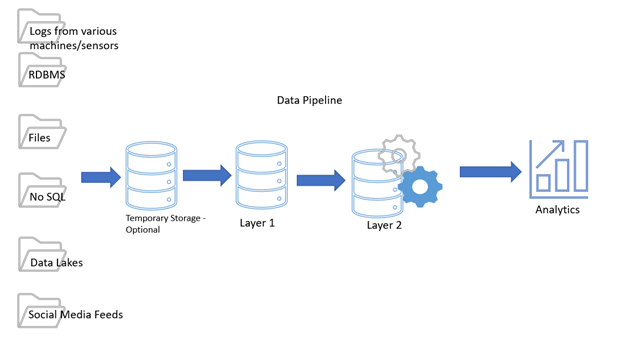
- The necessary process involves the below steps: Data sources and their Generation
- Collection from polling services such as EC2, S3 etc which pull real-time data
- Storage – Huge data is stored in S3 or amazon RDS using many engines or EC2 in some cases.
- ETL – Extract – Transform – Load – this process becomes complex with the data volume getting doubled very fast. Data comes from many more resources now in different formats and structures. ETL is critical in terms of data privacy and security. EMR, Lambda, Connexis etc offer similar features, but AWS glue automates this ETL
- Analyze – Nest phase is consuming this data to understand, utilize the information being delivered and extract insights which were the primary goals for this process.
- And then Visualize in reports or dashboards using various BI tools available such as Tableau, Qlikview, dashboards etc various applications can be used.
In the AWS environment, S3, RDS, EC2, DynamoDB, and Aurora are types of data sources. S3 can even be used as a data lake.
Cloud Data warehouse includes Amazon Redshift as Redshift is flexible, scalable, and can handle loads hence improving transformation speed even after loading therefore transformations are now run after the loading even give better performance.
What is AWS Glue
It is a cloud, optimized ETL process. It allows to organize, locate, move and transform the data across the business for better usability.
Glue offers 3 additional features as compared to other products.
- Glue is serverless – Point and run — it runs ETL jobs automatically. No need to set up servers and monitor the lifecycle.
- Glue offers compatibility with semi-structured as well as structured data sets. The crawlers automatically discover data sets, file types, extract schema and build centralized metadata for the ease of use.
- Glue even automatically generates the script needed to extract and transform the data to be loaded from source to target.
This has significantly reduced the time then taken for mapping, organizing, moving the data across the pipeline, and loading to the target.

Alternatives With Feature Variations
- Informatica PowerCenter.
- Talend Data Integration.
- Azure Data Factory.
- Pentaho Data Integration.
- SAP HANA.
Daton is an automated data pipeline which extracts data from multiple sources for replicating them into data lakes or cloud data warehouses like Snowflake, Google Bigquery, Amazon Redshift where employees can use it for business intelligence and data analytics. It has flexible loading options which will allow you to optimize data replication by maximizing storage utilization and easy querying. Daton provides robust scheduling options and guarantees data consistency. The best part is that Daton is easy to set up even for those without any coding experience. It is the cheapest data pipeline available in the market. Sign up for a free trial of Daton today!!