Over the last 15 years, there has been significant growth in the adoption of software-as-a-service (SaaS) applications. It has been decomposed into the best-of-the-breed SaaS applications, which used to be monolithic applications supporting various business functions like Finance, CRM, inventory, Asset Management, customer support, and manufacturing. A company using monolithic applications may now use multiple SaaS applications to do the same functions.
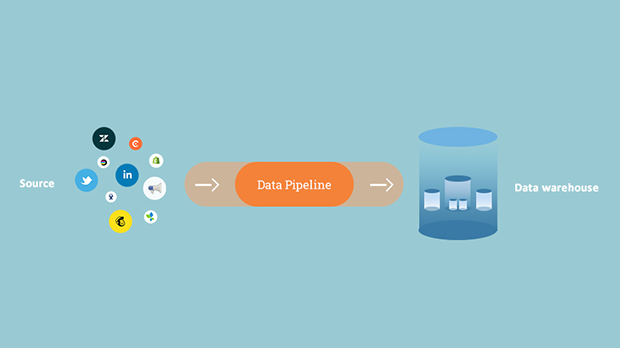
At its core, the data pipelines work to transfer data from the source point to the destination. Different processes involve moving and unifying data to make it easily accessible for the business team. The architecture of the data pipeline describes the data pipeline setup to ensure accessible data collection, data flow, and data delivery. If you are looking to get started with data pipelines, it is vital to understand the concept from the root. Keep reading, as we have covered all the main points about data pipelines in the article.
What is a Data Pipeline?
Simply put, a data pipeline means a sequence of steps that move data (raw) from one point to another. For instance, when you move data in business intelligence, the data flow from a data warehouse or data lake to a transactional database. At the destination point, the received data is analyzed to get insights into the business. While the transfer of data via data pipeline, the transformation logic is also applied to make the data flowing apt for analysis.
Why do you need to opt for a data pipeline?
In today’s high-paced modern era, numerous business owners use different apps to store information or other functions. For instance, your marketing team might use Marketo and HubSpot, whereas your sales team might rely on Salesforce. The diversity of data on a suite of apps can lead to data fragmentation which, in turn, leads to data silos.
Data silos make it difficult for team members to fetch simple business insights. Even if you somehow manage to fetch the required data and move it into Excel Sheets, it might be hard for you to deal with errors. In this case, the manual data fetching process can lead to errors like data redundancy.
Besides, the complexity level involved in the process is quite high, making it hard for you to analyze data in real time. All you need is a data pipeline to resolve such issues and avoid errors. It is one of the surefire ways to gather data from different sources to a single destination. Furthermore, easy access to crucial data will help one to get reliable business insights easily.
Types of data that can pass through data pipeline solutions
There are two types of data passing through the data pipelines. These include:
Structured Data
It is the data that is in a fixed format. You can save or retrieve the data in the same format. Some of the best examples of this data include phone numbers, email addresses, banking information, IP address, and much more.
Unstructured Data
Unlike structured data, you will not be able to track unstructured data in a fixed format. Some of the best examples of unstructured data include mobile phone searches, email content, social media comments, online reviews, mobile phone searches, and much more.
If you wish to extract business insights easily, you must choose the right data pipeline. The dedicated infrastructure of the data pipeline will help you to migrate data effectively and smoothly.
Major elements of the data pipeline
To get in-depth knowledge about the data pipeline, it is vital to understand its major elements. We have listed the major elements of the data pipeline that you can check out.
Source
This is the place from where the data can be extracted. Some of the most common data sources include IoT device sensors, CRMs, ERPs, social media management tools, relational database management systems (RDBMS), and more.
Destination
All the data extracted from the source is dumped at the destination. In most cases, the destination can be a data warehouse or data lake. This is the same place where the data is stored for further analysis. In other cases, the data can be directly dumped into the data visualization tools.
Processing
When the data moves from one place to another, it undergoes a few changes. Amongst all the data flow approaches, the most common one is ETL (Extract, Transform and Load).
Read more on ETL vs ELT.
Destination
This is one of the most important components of data migration. It involves processing steps of data flow from source to destination. In this component, the type of extract process for data extraction is analyzed before execution.
Workflow
This step involves the sequencing of jobs in the data pipeline. According to the workflow, the upstream job needs to be accomplished before the beginning of the downstream job.
Monitoring
Data accuracy and data loss in the data pipeline must be constantly monitored. In addition, as the size of the data pipeline grows larger over time, it is important to keep an eye out for the speed and efficiency of data pipelines.
Types of data pipelines
When understanding data pipelines or choosing one, you need to pay attention to the different types of data pipelines. These include:
Batch Processing
The data is processed periodically and regularly during batch processing in the data pipeline. However, during batch-based processing, the data transfer and processing take longer. Therefore, if a business owner needs to move large amounts of data without extra effort, they can choose a batch processing method.
Stream Processing
Opposite to batch-based data processing, stream processing transfer and process the data as soon as the data gets created. So, the companies who wish to process data as fast as possible to understand the latest industry trends, all you need to do is choose stream processing.
Open Source
Open-source solutions have traditionally been the go-to for developers and companies trying to avoid the more expensive Enterprise-grade data pipeline solutions. However, these traditional tools require technical expertise from the team and are often supported only by the community. Pentaho and Apache NIFI are a couple of such examples.
Real-Time or Streaming
As the name suggests, these tools move data from sources to destinations in real time. Many use cases require real-time data management to support various activities around real-time personalization, IoT, financial markets, and end telemetry. Stream sets, Amazon Kinesis, and Google Data Flow are a few examples.
Cloud-Native or SaaS Data Pipelines
These are the more modern applications that have been designed it support analysts and data scientists in a data-driven company. These applications run in the cloud, offer subscription-based services, and are often more economical than the applications that have been in use traditionally. They also alleviate the burden of management from resources in charge of pipeline maintenance, thereby freeing up their time for more productive applications. Stitch Data, Fivetran, and Blendo are some examples of the model ELT-based data pipelines.
Key features of the modern data pipeline
If you feel your business needs to choose modern data pipelines, here are a few you need to look for. Having the best data pipeline will help your team make fast business decisions and ensure that the decisions made are accurate.
Quick Data Processing & Analytics
Finding quick business insight from a ton of complex data is no easy feat. That is why data pipelines must extract, transform, and analyze the data in no time. This will help businesses to find the required business insights and act on them responsibly. Change Data Capture is one of the best ways to get real-time data and insights without extra effort.
As a business owner, one must always prefer continuous or real-time data processing to batch-based processing. This is because batch-based processing can lead to hours of time wastage in extracting and transferring data.
Excessive time can lead to inefficient tracking of security threats or delay analyzing a social media trend. Both delays can lead to significant loss to a business owner. Choosing the data pipelines that offer quick business insight will help business owners with more current data.
Scalable Cloud-Based Infrastructure
Another best feature of modern data pipelines is the scalable cloud-based infrastructure. Unlike traditional data pipelines, you can easily handle multiple workloads with modern data pipelines. Thanks to the scalable cloud-based infrastructure of modern data pipelines, it is quite easy to compute resources and distribute them into independent clusters. As clusters grow infinitely and easily, it helps reduce data processing time and improve data storing efficiency. Furthermore, they are agile and elastic, which helps you to take advantage of multiple business trends.
High Reliability
Data pipeline failure has become a common problem during data migration. To solve this complication, modern data pipelines come with reliable architecture. The distributed architecture instantly alters the user if application failure, node failure, or certain service failure happens during the data migration. In case any node failure happens in the modern data pipelines, the active node immediately replaces the failed node and carries out the task without any extra interventions.
Exactly One Processing
During the data migration task, the user must deal with data duplication and loss. However, a modern data pipeline can help solve data duplication and data loss problems. Thanks to the checkpointing capabilities, you will not have to deal with missed data or twice processed data. The feature keeps an eye out for how the data is being processed and how far the data has gone. In case of failure, the data replay feature of the modern data pipelines will allow one to analyze the data processing process by rewinding it.
High Data Volume Processing
Studies reveal that the data production amount will reach nearly 463 exabytes by 2025. As 80% of the complete business idea consists of semi-structured and unstructured data, modern data pipelines need to have a large volume of data processing features.
Incorporating data pipelines into business is extremely important for easy management of data. That is why one must analyze the features of the data pipeline to choose the fit business needs and preferences and help one overcome the most common challenges.
When to switch to an Agile data pipeline?
Here are a few indicators that will help you make a call regarding switching an agile data pipeline.
Struggling to extract full value from your data
Business data is, undoubtedly, one of the most important things for your business. Using data in the right way can help you to do your business. Critical business insights can boost performance, business profitability, and organizational efficiency. However, many business owners often struggle with extracting the best value from their business data. If you are struggling with the same, you must choose the best data pipeline. Modern data pipelines come with advanced BI and analytics features. It will help you to extract vital business insights in real time, ensuring that your business stays ahead of the competition.
Low Data Utilization
Even though the world is becoming increasingly digitized, it has become quite hard for businesses to utilize their data to the full extent. As a result, fewer business insights and less visibility push businesses back into the competition. This is where the use of data pipelines comes into the picture. Advanced and modern data pipelines help the user with real-time and detailed business insight that helps in easy movement and preparation of data for integration and data analysis.
High volumes of data
When your company scales, the data accumulation also gets higher. This, in turn, will make it hard for your in-house team to extract important information from data successfully. In such cases, looking for advanced tools and technologies like modern data pipelines is vital. These pipelines are equipped with extra features that make it easy for business owners to extract the necessary information and use it to grow the business. In short, a data pipeline helps easily process, extract, and transfer large volumes of data.
Why should you opt for Daton- our eCommerce-focused data pipeline?
An eCommerce focused data pipeline helps transforming your raw eCommerce data into usable reporting! These data pipelines comprise of certain workflows within your pipelines that answer a specific set of questions. Some workflow examples include:
| Workflow Type | Insights that can be drawn |
| Buyer segmentation |
|
| Cart analysis |
|
| Sales forecasting |
|
Using a traditional data pipeline, building, and maintaining a data pipeline in-house is a cumbersome process. Reasons why businesses should avoid the traditional method of data pipelines-
- The process takes longer to deliver business value.
- Need to build-out APIs to pull data from a variety of data sources.
- Manage the APIs as they go through various changes throughout the year.
- Build a notification system that alerts you when the system or data quality issues occur.
- Manage the code base and continue delivering quality data while resources move in and out of the team.
- Must build a monitoring system to monitor the performance and validity of the data passing through the pipeline.
- Requires expensive resources to build and operate the system.
Daton offers a cost-effective, straightforward way to handle eCommerce data pipelines. It is a leading cloud-based, fully managed, secure, and scalable data pipeline. Here are a few reasons why you should switch to Daton-
- Data replication takes minutes, not months.
- You do not need to build out APIs to pull data from various data sources.
- API management is not required as they undergo various changes throughout the year.
- Presence of a built-in monitoring system that monitors the performance and validity of the data passing through the pipeline.
- A built-in notification system that alerts you when there are system or data quality issues
- Automatically handles changes in the schema in both the destination and the source.
- Get continuous delivery of quality data.
- Inexpensive, fast, and scalable as your data demand grows.
- Fully supported by a team of resources 24X7 governed by SLAs.
- Highly secure infrastructure to ensure data security.
With Daton, you can bring data from over 140 sources like databases, flat flies, and applications using our data connectors into a data warehouse of your choice. With an easy all-in-one data integration, you can get data from various data connections with a quick access to all the information needed to draw insights from. Get customizable enterprise reporting and analytics and own your data.
Conclusion
Regardless of your technologies, a data pipeline is considered the heart of your data infrastructure. At its core, it functions to transfer data to different applications and systems. Furthermore, it assists in delivering high-level and robust business intelligence solutions to improve the entire organization’s functions. Having an agile, modern data pipeline like Daton will assist you not only in improving internal business operations but also ensure that you are ready to gain more customers. Sign up for a 14-day free trial today!